Refining the Optimizer¶
All is one
We're going to replace the Pytorch Optim with a custom optimizer class that uses steppers.
This will allow us to make one Optimizer that can do any type of step we want to define.
It can do a SGD step, a momentum step, a weight decay step, or an Adam step.
%reload_ext autoreload
%autoreload 2
%matplotlib inline
#export
from exp.nb_09a import *
Imagenette Data & Baseline Model¶
path = datasets.untar_data(datasets.URLs.IMAGENETTE_160) # downloads and returns a path to folder
tfms = [make_rgb, ResizeFixed(128), to_byte_tensor, to_float_tensor] # transforms to be applied to images
bs = 128
il = ImageList.from_files(path, tfms=tfms) # Imagelist of filenames from path
sd = SplitData.split_by_func(il, partial(grandparent_splitter, valid_name="val")) # Splitdata by folder function
ll = label_by_func(sd, parent_labeler, proc_y=CategoryProcesser()) # label the data by parent folder
data = ll.to_databunch(bs, c_in=3, c_out=10)
nfs = [32,64,128,256]
callbacks = [partial(AvgStatsCallback, accuracy),
CudaCallback,
partial(BatchTransformXCallback, norm_imagenette)]
learn, run = get_learn_run(data, nfs,conv_layer, 0.3, cbs=callbacks)
run.fit(1, learn)
Our baseline model using vanilla SGD gives us around 45% validation accuracy in one epoch.
run.fit(8, learn)
If we train it a bit further we are up to 62% validation accuracy.
SGD¶
We're going to stop using the Pytorch optim and write an SGD optimizer from scratch.
Then we'll take this basic optimizer structure and iterate on it to add different regularization and optimization algorithms.
Optimizer class v1¶
The Optimizer class at its core will store a dictionary of parameters and hyper-parameters and apply a function to the parameters using the hyperparameters and some stepper function when step is called after each batch .
Parameters will be stored in param_groups which is a list of lists:
self.param_groups = [[pg1], [pg2], [pg3]]
And each param_group will have a corresponding hyper-parameter dictionary in the list self.hyper:
self.hyper = [{'lr': 0.2,'wd':0.}, {'lr': 0.1,'wd':0.}, {'lr': 0.4,'wd':0.}]
class Optimizer():
def __init__(self, params, steppers, **defaults):
self.param_groups = list(params)
# ensure params is a list of lists
if not isinstance(self.param_groups[0], list):
self.param_groups = [self.param_groups]
self.hypers = [{**defaults} for p in self.param_groups]
self.steppers = listify(steppers)
def grad_params(self):
return [(p, hyper) for pg, hyper in zip(self.param_groups, self.hypers) for p in pg if p.grad is not None]
def zero_grad(self):
for p,hyper in self.grad_params(): # iterates through
p.grad.detach_() # removes gradient computation history
p.grad.zero_() # zeros the grads for next batch
def step(self):
for p, hyper in self.grad_params(): # does nothing without steppers
compose(p, self.steppers, **hyper)
SGD stepper¶
Takes p a parameter and the lr hyperparameter, a scalar, and adds the gradient of the parameter multiplied by the negative learning rate.
#export
def sgd_step(p, lr, **kwargs):
p.data.add_(-lr, p.grad.data)
return p
opt_func = partial(Optimizer, steppers=[sgd_step])
Refactor Callbacks¶
We'll need to refactor some of our callbacks to work with the new optimzer
#export
class AvgStats():
def __init__(self, metrics, in_train):
self.metrics = listify(metrics)
self.in_train = in_train
def reset(self):
self.tot_loss = 0.
self.count = 0
self.tot_mets = [0.]*len(self.metrics)
@property
def all_stats(self):
return [self.tot_loss.item()] + [o.item() for o in self.tot_mets]
@property
def avg_stats(self):
return [o/self.count for o in self.all_stats]
def __repr__(self):
if not self.count: return "Something went wrong: count is zero."
if self.in_train:
return f"Train: {[round(o,4) for o in self.avg_stats]}"
else:
return f"Valid: {[round(o,4) for o in self.avg_stats]}\n"
def accumulate(self, run):
bn = run.xb.shape[0]
self.tot_loss += run.loss * bn
self.count += bn
for i, m in enumerate(self.metrics):
self.tot_mets[i] += m(run.pred, run.yb) * bn
class AvgStatsCallback(Callback):
def __init__(self, metrics):
self.train_stats = AvgStats(metrics, True)
self.valid_stats = AvgStats(metrics, False)
def begin_epoch(self):
self.train_stats.reset()
self.valid_stats.reset()
def after_loss(self):
stats = self.train_stats if self.in_train else self.valid_stats
with torch.no_grad():
stats.accumulate(self.run)
def after_epoch(self):
print(self.train_stats)
print(self.valid_stats)
Recorder will have to be re-written to work with this new optimizer. We had been pulling everything from Pytorch's opt.param_groups.
Now to get the learning rate we access self.opt.hypers
#export
class Recorder(Callback):
def begin_fit(self):
self.losses = []
self.lrs = []
def after_batch(self):
if not self.in_train: return
self.lrs.append(self.opt.hypers[-1]['lr'])
self.losses.append(self.loss.detach().cpu())
def plot_loss(self): plt.plot(self.losses)
def plot_lr (self): plt.plot(self.lrs)
def plot(self, skip_last=0):
losses = [o.item() for o in self.losses]
n = len(losses)-skip_last
plt.xscale('log')
plt.plot(self.lrs[:n], losses[:n])
The ParamScheduler now needs to go through all of our self.opt.hypers and apply its scheduler functions accordingly.
Remember each Param we schedule gets a different ParamScheduler callback - so each one is only accessing one self.pname in self.opt.hypers at a time.
#export
class ParamScheduler(Callback):
_order = 1
def __init__(self, pname, sched_funcs):
self.pname = pname
self.sched_funcs = listify(sched_funcs)
def begin_batch(self):
if not self.in_train: return # end if not in train mode
fs = self.sched_funcs # list of scheduler funcs
if len(fs)==1: # if only 1 scheduler multiple it and use it for each group
fs = fs*len(self.opt.param_groups)
pos = self.n_epochs/self.epochs # position in training
for scheduler, hyper in zip(fs, self.opt.hypers):
hyper[self.pname] = scheduler(pos) # change the pname according to the scheduler
Similarly, the LR_Find now needs to use opt.param_groups
#export
class LR_Find(Callback):
_order = 1
def __init__(self, max_iter=100, min_lr=1e-6, max_lr=10):
self.max_iter = max_iter
self.min_lr = min_lr
self.max_lr = max_lr
self.best_loss = 1e9
def begin_batch(self):
if not self.in_train: return
pos = self.n_iter/self.max_iter
lr = self.min_lr * (self.max_lr/self.min_lr) ** pos
for pg in self.opt.hypers: pg['lr'] = lr # change from opt.param_groups
def after_step(self):
if self.n_iter >= self.max_iter or self.loss > self.best_loss*10:
raise CancelTrainException
if self.loss < self.best_loss:
self.best_loss = self.loss
SGD Test¶
sched = combine_scheds([.3, .7], [sched_cos(.3, .6), sched_lin(.6, 0.2)])
callbacks = [partial(AvgStatsCallback, accuracy),
CudaCallback, Recorder,
partial(ParamScheduler, 'lr', sched)]
learn, run = get_learn_run(data, nfs, conv_layer, 0.3, cbs=callbacks, opt_func=opt_func)
run.fit(1, learn)
run.recorder.plot_loss()
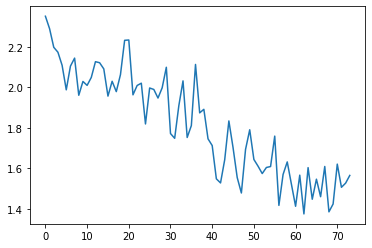
run.recorder.plot_lr()
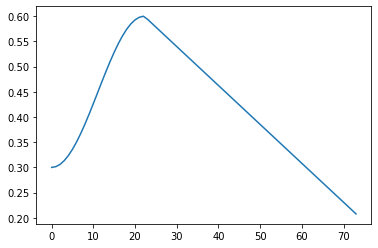
run.fit(8, learn)
We get about the same validation accuracy.
run.recorder.plot_loss()
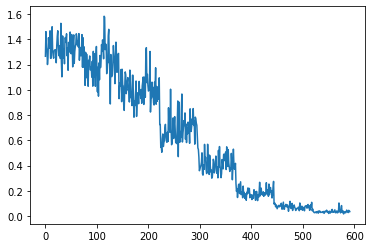
Our loss has a step like quality to it. Each epoch the variance appears to be decreasing in
Param Groups¶
Let's compare our model_summary to the grad_params() method of our Optimizer:
model_summary(run, learn, data)
gp = learn.opt.grad_params()
len(gp)
Parameter and hyperparameter for the Conv2d layer of the first block:
gp[0][0].shape, gp[0][1]
The next layer that has parameters would be the BatchNorm2d layer.
It has two learnable parameters: mults ($\gamma$) and adds ($\beta$) from the BatchNorm nb:
gp[1]
gp[2]
for p in learn.model[0][2].parameters(): print(p)
Regularization¶
Now that we have SGD let's add some regularization.
L2 Regularization¶
L2 regularization is a penalty term added to the loss in order to minimize the weights.
It's generally $\lambda$ (the L2 parameter) multiplied by the sum of the weights squared:
loss_with_L2 = loss + L2 * (weights**2).sum()
It is computationally inefficient to square and sum the weights for each batch and then add them to the loss and compute the gradients.
Instead we can take the gradient of the weights and multiple it by a weight decay parameter wd (L2 above) and add that to the gradient.
These two equations are equivalent:
loss_with_L2 = loss + (L2) * (weights**2).sum()
weight.grad += wd * weight
Full update looks like this:
new_weight = weight - lr * (weight.grad + wd * weight)
We'll make a l2_reg stepper which uses the computationally more efficient way of adding the gradients times the wd parameter to the weight gradients:
#export
def l2_reg(p, lr, wd, **kwargs):
p.grad.data.add_(wd, p.data) # scalar times parameter and then add to gradient
return p
l2_reg._defaults = dict(wd=0.)
Weight Decay¶
If we factor this further:
new_weight = weight - (lr * weight.grad) - (lr * wd * weight)
When we decay each weight by a factor lr * wd, it's called weight decay
The weight_decay stepper will be applied before the sgd_step:
def sgd_step(p, lr, **kwargs):
p.data.add_(-lr, p.grad.data)
return p
Therefore, all the weight_decay stepper needs to do is subtract lr * wd * weights from the weights.
new_weight = weights - lr * wd * weights
new_weight = weights * (1-lr*wd)
Or multiple the weights by 1-lr*wd
#export
def weight_decay(p, lr, wd, **kwargs):
p.data.mul_(1 - lr*wd)
return p
weight_decay._defaults = dict(wd=0.)
Decoupled Weight Regularization by Ilya Loshchilov and Frank Hutter, it is better to use the second one with the Adam optimizer.
Optimizer class v2¶
Our next optimizer is nearly identical to the first but add in a function to collect the defaults of the steppers to the self.hyper list of default hyperparameter dictionaries
#export
def get_defaults(d):
return getattr(d, "_defaults", {})
get_defaults(sgd_step)
#export
def maybe_update(steppers, dest, func):
for s in steppers:
for k,v in func(s).items():
if not k in dest: dest[k] = v
#export
class Optimizer():
def __init__(self, params, steppers, **defaults):
self.steppers = listify(steppers) # add stepper functions
maybe_update(self.steppers, defaults, get_defaults) # get defaults
self.param_groups = list(params)
if not isinstance(self.param_groups[0], list):
self.param_groups = [self.param_groups]
self.hypers = [{**defaults} for p in self.param_groups] # make dict of hyper
def grad_params(self):
return [(p, hyper) for pg, hyper in zip(self.param_groups, self.hypers)
for p in pg if p.grad is not None]
def zero_grad(self):
for p, hyper in self.grad_params():
p.grad.detach_()
p.grad.zero_()
def step(self):
for p, hyper in self.grad_params():
compose(p, self.steppers, **hyper)
Weight Decay Test¶
#export
sgd_opt = partial(Optimizer, steppers=[weight_decay, sgd_step])
learn, run = get_learn_run(data, nfs, conv_layer, 0.3, cbs=callbacks, opt_func=sgd_opt)
Check defaults:
model = learn.model
opt = sgd_opt(model.parameters(), lr=0.1)
test_eq(opt.hypers[0]['wd'], 0.)
test_eq(opt.hypers[0]['lr'], 0.1)
It works as expected.
If we change the default wd to 1e-4 its the value we find in the opt.hypers
opt = sgd_opt(model.parameters(), lr=0.1, wd=1e-4)
test_eq(opt.hypers[0]['wd'], 1e-4)
test_eq(opt.hypers[0]['lr'], 0.1)
Now we'll train with Weight Decay:
callbacks = [partial(AvgStatsCallback,accuracy), CudaCallback,
partial(BatchTransformXCallback, norm_imagenette),
Recorder, partial(ParamScheduler, 'lr', sched)]
Small weight decay of 0.0001
learn, run = get_learn_run(data, nfs, conv_layer, 0.3, cbs=callbacks, opt_func=partial(sgd_opt, wd=1e-4))
run.fit(8, learn)
run.recorder.plot_loss()
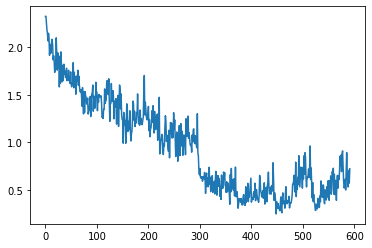
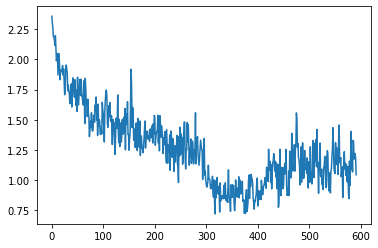
Its interesting that after epoch 5 the validation loss starts fluctuating and increasing.
Now let's try a larger weight decay of 0.01
learn, run = get_learn_run(data, nfs, conv_layer, 0.3, cbs=callbacks, opt_func=partial(sgd_opt, wd=0.01))
run.fit(8, learn)
run.recorder.plot_loss()
Momentum¶
Momentum helps to accelerate SGD and dampen oscillations.
The update is pretty simple:
$$\begin{align} \begin{split} v_t &= \gamma v_{t-1} + \eta \nabla_\theta J( \theta) \\ \theta &= \theta - v_t \end{split} \end{align}$$For momentum we need our Optimizer to be able to hold a state - namely, the exponentially decaying average of the gradients.
#export
class StatefulOptimizer(Optimizer):
def __init__(self, params, steppers, stats=None, **defaults):
self.stats = listify(stats)
maybe_update(self.stats, defaults, get_defaults)
super().__init__(params, steppers, **defaults)
self.state = {}
def step(self):
for p, hyper in self.grad_params():
if p not in self.state:
self.state[p] = {}
maybe_update(self.stats, self.state[p], lambda o: o.init_state(p))
state = self.state[p]
for stat in self.stats:
state = stat.update(p, state, **hyper)
compose(p, self.steppers, **state, **hyper)
self.state[p] = state
Stat abstract base class: two methods need to be implemented by user.
#export
class Stat():
_defaults = {}
def init_state(self, p):
raise NotImplementedError
def update(self, p, state, **kwargs):
raise NotImplementedError
AverageGrad stat:
class AverageGrad(Stat):
_defaults = dict(mom=0.9)
def init_state(self, p):
return {'grad_avg': torch.zeros_like(p.grad.data)}
def update(self, p, state, mom, **kwargs):
state['grad_avg'].mul_(mom).add_(p.grad.data)
return state
Momentum step:
#export
def momentum_step(p, lr, grad_avg, **kwargs):
p.data.add_(-lr, grad_avg)
return p
sgd_mom_opt = partial(StatefulOptimizer, steppers=[momentum_step, weight_decay], stats=AverageGrad(), wd=0.01)
Momemtum with normalized batches:
learn, run = get_learn_run(data, nfs, conv_layer, 0.3, cbs=callbacks, opt_func=sgd_mom_opt)
run.fit(1, learn)
And without normalized batches:
callbacks = [partial(AvgStatsCallback,accuracy), CudaCallback,
Recorder, partial(ParamScheduler, 'lr', sched)]
learn, run = get_learn_run(data, nfs, conv_layer, 0.3, cbs=callbacks, opt_func=sgd_mom_opt)
run.fit(1, learn)
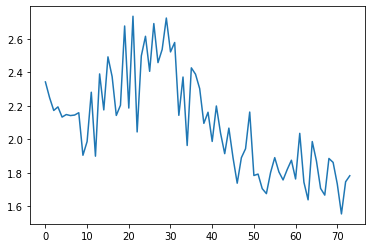
run.recorder.plot_loss()
Momentum experiments¶
In order to understand what momentum does to our gradients, let's start by creating some fake data and plotting some simple calculations.
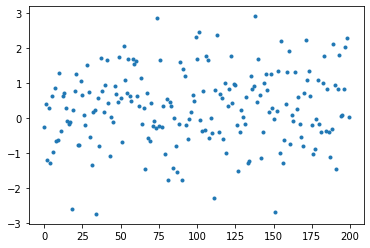
y will be a tensor of 200 elements with a mean of 0.3
y = torch.randn(200) + 0.3
betas is an array of 4 numbers between 0.5 and 0.99 we'll use for our beta value
betas = [0.5, 0.7, 0.9, 0.99]
And by plotting our y we can see how they are spread out.
plt.plot(y, linestyle='None', marker='.');
plot_mom will create a figure with 4 subplots that each calculates a function given a beta value, an avg which it will find, an element from y and a y index number.
def plot_mom(f):
# create 4 subplots
_, axs = plt.subplots(2,2, figsize=(12, 8))
# for each subplot plot y and some res calculated by f
for beta, ax in zip(betas, axs.flatten()):
ax.plot(y, linestyle='None', marker='.')
avg = None
res = []
for i, yi in enumerate(y):
avg, p = f(avg, beta, yi, i)
res.append(p)
ax.plot(res, color='red')
ax.set_title(f'beta={beta}')
Regular momentum¶
Just add a fraction ($\beta$) of the average to the output:
def mom1(avg, beta, yi, i):
if avg is None: avg=yi
res = beta*avg + yi
return res, res
As the beta term increases, more and more of the average is added to the output.
As this happens the scale of the output diverges from the data we're attempting to map to.
plot_mom(mom1)
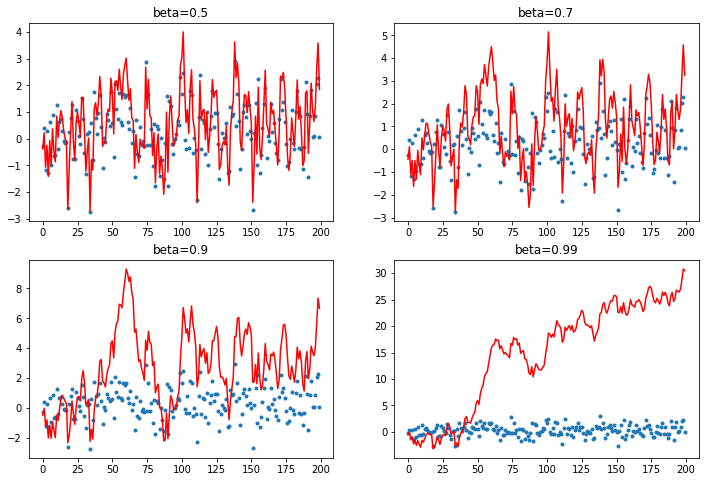
When the beta term is too high we end up adding too much of the avg and our prediction shoots off - this can happen in training.
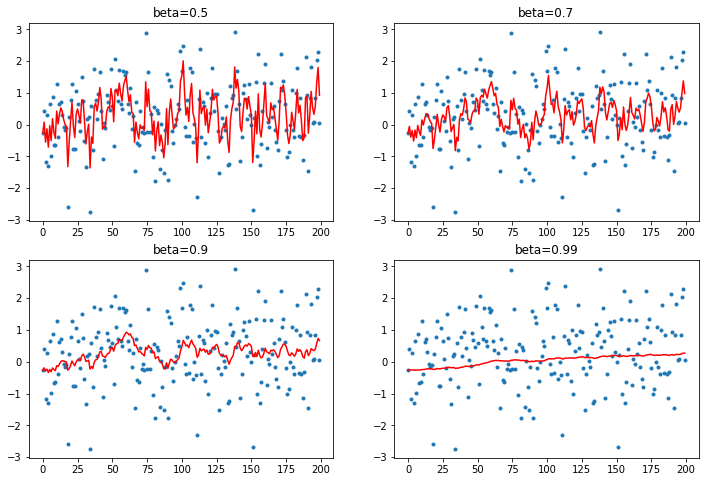
EWMA Momentum¶
Instead of just taking the average, let's add a mixture of the previous signal and the current signal using an exponentially weighted moving average.
$$ S_i = \beta S_{i-1} + (\beta -1)x_i$$def lin_comb(beta, s, x):
return beta*s + (1-beta)*x
def mom2(avg, beta, yi, i):
if avg is None: avg=yi
res = lin_comb(beta, avg, yi)
return res, res
plot_mom(mom2)
Mapping to function¶
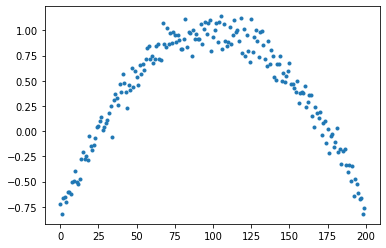
Let's turn out y into a quadratic.
x is 200 evenly spaced numbers between -4 and 4
x = torch.linspace(-4, 4, 200)
We'll subtract 1 to flip the parabola. Divide by 3 to scale it. Add some random noise with a mean of 0.1
y = 1 - (x/3)**2 + torch.randn(200) * 0.1
plt.plot(y, linestyle='None', marker='.');
Now let's change the first term to be an outlier of 0.5. This will demonstrate how the EWMA is deformed by the first batch.
y[0] = 0.5
plot_mom(mom2)
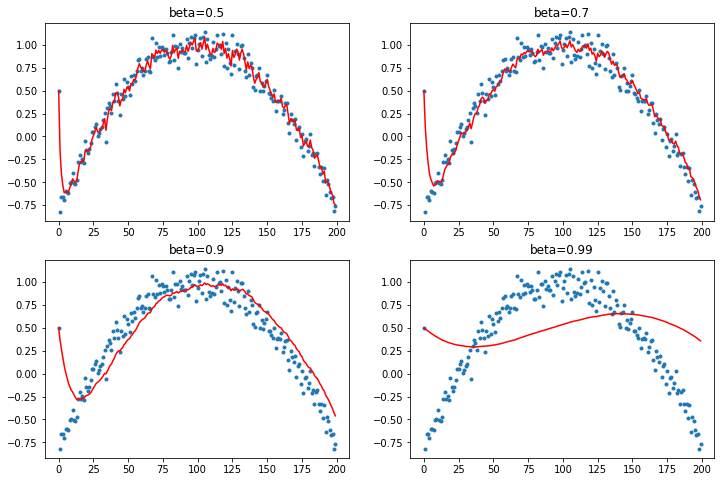
The first element biases the prediction, especially when the beta value is higher like 0.99. Too much of momentum's influence comes from this EWMA and if the first terms are off then it struggles to recover a good fit.
And when the beta term is 0.9 the average is running behind - because momentum is adding the past steps to calculate where it should be going as the data moves in a direction it is slow to adjust.
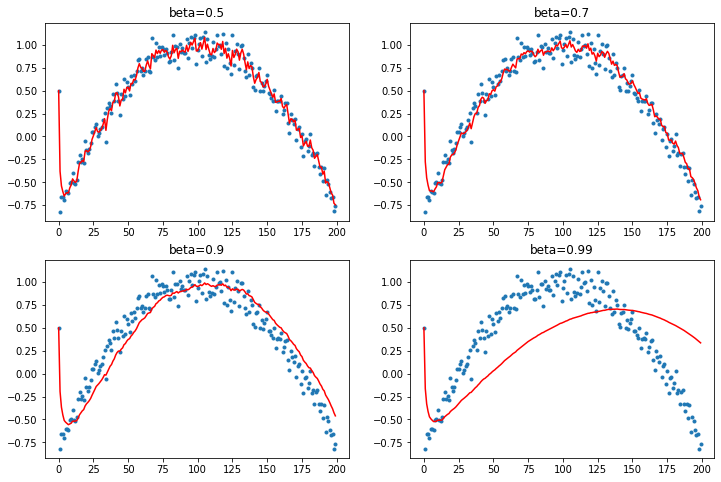
Debiasing
We would like to correct this tendency of Momentum to get thrown off because of the early data.
So we'll divide the average by a debiasing terms that corresponds to the sum of the coefficients in our moving average.
def mom3(avg, beta, yi, i):
if avg is None: avg=0
avg = lin_comb(beta, avg, yi)
return avg, avg/(1-beta**(i+1))
plot_mom(mom3)
Adam¶
Adaptive Moment Estimation from the paper: Adam: A Method for Stochastic Optimization
Adam stores two moving averages:
- The exponentially decaying average of the past gradients, like momentum (mean, first moment).
- The exponentially decaying average of the past squared gradients (variance, the second moment).
And then to debias these:
$$\begin{align} \begin{split} \hat{m}_t &= \dfrac{m_t}{1 - \beta^t_1} \\ \hat{v}_t &= \dfrac{v_t}{1 - \beta^t_2} \end{split} \end{align}$$The update rule is as follows:
$$ \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t$$Adam Stats:¶
In order to compute $m_t$ above we need an AverageGrad stat
#export
class AverageGrad(Stat):
_defaults = dict(mom=0.9)
def __init__(self, dampening: bool=False):
self.dampening = dampening
def init_state(self, p):
return {'grad_avg': torch.zeros_like(p.grad.data)}
def update(self, p, state, mom, **kwargs):
state['mom_damp'] = 1-mom if self.dampening else 1.
state['grad_avg'].mul_(mom).add_(state['mom_damp'], p.grad.data)
return state
And the compute $v_t$ we need an AverageSqrGrad
#export
class AverageSqrGrad(Stat):
_defaults = dict(mom=0.99)
def __init__(self, dampening: bool=False):
self.dampening = dampening
def init_state(self, p):
return {'sqr_avg': torch.zeros_like(p.grad.data)}
def update(self, p, state, sqr_mom, **kwargs):
state['sqr_damp'] = 1-mom if self.dampening else 1.
state['sqr_avg'].mul_(sqr_mom).addcmul_(state['sqr_damp'], p.grad.data, p.grad.data)
return state
And a StepCount stat:
#export
class StepCount(Stat):
def init_state(self, p):
return {'step': 0}
def update(self, p, state, **kwargs):
state['step'] += 1
return state
Adam Step¶
Debiasing:
$$ \begin{align} \begin{split} \hat{m}_t &= \dfrac{m_t}{1 - \beta^t_1} \\ \hat{v}_t &= \dfrac{v_t}{1 - \beta^t_2} \end{split} \end{align}$$#export
def debias(mom, damp, step):
return damp * (1-mom**step) / (1-mom)
Adam step calculates the debiased exponentially decaying averages and it is just the update rule above:
$$ \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t$$#export
def adam_step(p, lr, mom, mom_damp, step, sqr_mom, sqr_damp, grad_avg, sqr_avg, eps, **kwargs):
debias1 = debias( mom, mom_damp, step)
debias2 = debias(sqr_mom, sqr_damp, step)
p.data.addcdiv_(-lr/debias1, grad_avg, (sqr_avg/debias2).sqrt() + eps)
return p
adam_step._defaults = dict(eps=1e-5)
#export
def adam_opt(xtra_step=None, **kwargs):
return partial(StatefulOptimizer,
steppers=[adam_step, weight_decay] + listify(xtra_step),
stats=[AverageGrad(dampening=True), AverageSqrGrad(), StepCount()],
**kwargs)
learn, run = get_learn_run(data, nfs, conv_layer, 0.001, cbs=callbacks, opt_func=adam_opt())
run.fit(3, learn)
Lamb¶
nb_auto_export()