%reload_ext autoreload
%autoreload 2
%matplotlib inline
#export
from exp.nb_07 import *
BatchNorm¶
Layer Normalization
With basic parameter initialization we can only get so far. The next step would be normalize our activations inside the model.
This is idea behind BatchNorm and its many variants.
Data, Model, and Runner¶
We'll start how we normally do: get the mnist data, put together our callbacks, runner and learner and then train.
x_train, y_train, x_valid, y_valid = get_data()
train_ds, valid_ds = Dataset(x_train, y_train), Dataset(x_valid, y_valid)
nh,bs = 50,512
c = y_train.max().item()+1
loss_func = F.cross_entropy
data = DataBunch(*get_dls(train_ds, valid_ds, bs), c)
mnist_view = view_tfm(1,28,28)
callbacks = [
Recorder,
partial(AvgStatsCallback, accuracy),
partial(BatchTransformXCallback, mnist_view),
CudaCallback
]
nfs = [8,16,32,64,64]
learn, run = get_learn_run(data, nfs, conv_layer, lr=0.4, cbs=callbacks)
%time run.fit(3, learn)
Norms¶
Custom BatchNorm Module¶
We'll start by implementing BatchNorm from stratch based on the paper "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift" by Sergey Ioffe and Christian Szegedy
BatchNorm comes down to essentially 4 steps:
Find the mean of the mini-batch. $$ \mu_{\beta} \leftarrow \frac{1}{m} \sum_{i=1}^m x_i$$
Find the variance of the mini-batch: $$\sigma^2_{\beta} \leftarrow \frac{1}{m} \sum_{i=1}^m (x_i - \mu_{\beta})^2$$
Normalize the mini-batch by subtracting the mean and dividing by the squareroot of the variance plus a small value epsilon : $$ \hat{x}_i \leftarrow \frac{x_i - \mu_{\beta}}{\sqrt{\sigma_{\beta}^2 + \epsilon} }$$
Scale and shift: $$y_i \leftarrow \gamma \hat{x}_i + \beta \equiv BN_{\gamma, \beta}(x_i)$$
This is BatchNorm.
We'll implement this in a similar way as we created the Generalized ReLU - as a nn.Module which can easily be placed into our get_conv_layers function as any other module we're using (linear, Conv2d, etc)
class BatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps= 1e-5):
super().__init__()
self.mom, self.eps = mom, eps
# learnable parameters gamma and beta from the equation above
self.mults = nn.Parameter(torch.ones(nf, 1,1))
self.adds = nn.Parameter(torch.zeros(nf, 1,1))
# buffers that will be serialized and sent to the GPU but not optimized
self.register_buffer('vars', torch.ones(1,nf,1,1))
self.register_buffer('means', torch.zeros(1,nf,1,1))
def update_stats(self, x):
# mini-batch stats
m = x.mean((0,2,3), keepdim=True) # leaves a mean for each channel
v = x.var((0,2,3), keepdim=True)
# linear interpolation
self.means.lerp_(m, self.mom)
self.vars.lerp_(v, self.mom)
return m,v
def forward(self, x):
if self.training:
with torch.no_grad(): m,v = self.update_stats(x) # if train mode get stats of batch
else:
m,v = self.means, self.vars # if inference use saved means and vars
# normalize the batch
x = (x-m) / (v+self.eps).sqrt()
# scale and shift by learnable parameters
return x*self.mults + self.adds
register_buffer¶
We use the Pytorch register_buffer method for the mults and adds attributes. It adds some functionality that will helpful later:
1. Moves to GPU
2. When the model is saved/serialized later, it saves any tensors registered as buffers.
3. Buffers are not trained by the optimizer - they won’t be returned in model.parameters(), so that the optimizer won’t have a chance to update them.
If you have parameters in your model, which should be saved and restored in the state_dict, but not trained by the optimizer, you should register them as buffers.
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.my_tensor = torch.randn(1)
self.register_buffer('my_buffer', torch.randn(1))
self.my_param = nn.Parameter(torch.randn(1))
def forward(self, x):
return x
In this case my_tensor is not saved as a parameter or buffer - its simply a class attribute.
mm = MyModel()
print(mm.my_tensor)
There is only one parameter in the model:
for l in mm.parameters(): print(l)
And the state_dict contains my_param and my_buffer
print(mm.state_dict())
Now if we push everything onto the GPU we can see that the parameters and buffers get pushed onto the GPU but the my_tensor remains on the CPU:
mm.cuda()
print(mm.my_tensor)
print(mm.state_dict())
Mean of mini-batch¶
It's helpful for BatchNorm and the other types of Norm to keep in mind how average over a dimension:
a = torch.arange(1.,5.)
b = a.expand(3, 4); b
b.shape
The Pytorch mean function reduces over whichever dimension you give it.
Here we average over the rows (dim=0) and with keepdim=True we get a tensor of [1,4] with the average of every element in each row:
bm = b.mean(0, keepdim=True); bm, bm.shape
Doing the same thing for the columns (dim=1) we get:
bm = b.mean(1, keepdim=True); bm, bm.shape
Let's try this with a mini-batch of data.
A mini-batch starts as a rank 3 tensor. But conv2d function expects [batch_size, channels, height, width] so let's reshape it:
xb, yb = next(iter(data.train_dl))
xb = xb.view(512,1,28,-1); xb.shape
num_filters = 8
channels = 1
momentum = .1
The shape of our filter should be [number_of_filters, input_channels, height, width]
fil = torch.randn((num_filters,channels,5,5))
out = F.relu(F.conv2d(xb, fil, stride=2)); out.shape
Let's average over the 0,2,3 dimensions of the output tensor.
This means we will average over the mini-batch, height and width. Leaving us with a mean for each filter:
m = out.mean((0,2,3), keepdim=True); m.shape
Here we average over the 0 dim or rows - this results in a mean for every row - basically every image:
out.mean((1,2,3), keepdim=True).shape
And here the height and width:
out.mean((2,3), keepdim=True).shape
out.mean((0,1,3), keepdim=True).shape
lerp¶
Pytorch torch.lerp finds the exponentially weighted averaged in kind of a weird way.
Does a linear interpolation of two tensors `start` (given by input) and `end` based on a scalar or tensor weight and returns the resulting out tensor.
start_mean = torch.zeros(1,num_filters,1,1)
start_mean.lerp(m, momentum)
The normal equation for the exponentially weighted moving average is this:
$$ S_t = \alpha \cdot S_{t-1} + (1-\alpha) \cdot x $$Which gives us the same result:
.9*start_mean + (1.-.9)*m == start_mean.lerp(m, momentum)
Applying Custom BatchNorm¶
Now we'll need to tweak our conv_layer function to add a BatchNorm to each conv layer:
def conv_layer(ni, nf, ks=3, stride=2, bn=True, **kwargs):
# no bias if using bn
layers = [nn.Conv2d(ni, nf, kernel_size=ks, padding=ks//2, stride=stride, bias=not bn), GeneralRelu(**kwargs)]
if bn: layers.append(BatchNorm(nf, **kwargs))
return nn.Sequential(*layers)
Let's also refactor our init_cnn using the factory method and make a recursive init_cnn_ that traverses the model's modules:
#export
def init_cnn_(m, func):
if isinstance(m, nn.Conv2d):
func(m.weight, a=0.1)
if getattr(m, 'bias', None) is not None: m.bias.data.zero_()
for l in m.children(): init_cnn_(l, func)
def init_cnn(model, uniform=False):
initzer = init.kaiming_normal_ if not uniform else init.kaiming_uniform_
init_cnn_(model, initzer)
Reload get_learn_run with new functions:
#export
def get_learn_run(data, nfs, layer, lr, cbs=None, opt_func=None, uniform=False, **kwargs):
model = get_cnn_model(data, nfs, layer, **kwargs)
init_cnn(model, uniform=uniform)
return get_runner(model, data, lr=lr, cbs=cbs, opt_func=opt_func)
learn, run = get_learn_run(data, nfs, conv_layer, 0.4, cbs=callbacks)
with Hooks(learn.model, append_stats) as hooks:
run.fit(1, learn)
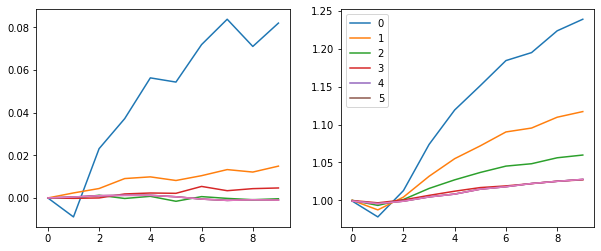
fig, (ax0, ax1) = plt.subplots(1,2, figsize=(10,4))
for h in hooks[:-1]:
ms, ss = h.stats[0], h.stats[1]
ax0.plot(ms[:10])
ax1.plot(ss[:10])
plt.legend(range(6))
fig, (ax0, ax1) = plt.subplots(1,2, figsize=(10,4))
for h in hooks[:-1]:
ms, ss = h.stats[0], h.stats[1]
ax0.plot(ms)
ax1.plot(ss)
plt.legend(range(6))
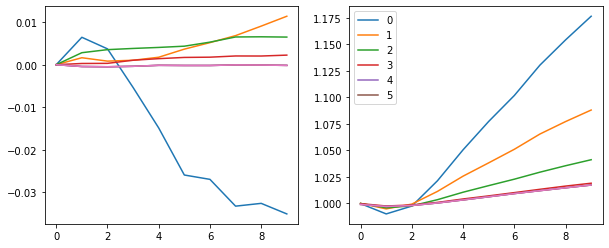
With a learning rate of 0.4 we get to 89% validation accuracy after 1 epoch.
Let's turn up the learning rate and see how our means and stds hold up.
learn, run = get_learn_run(data, nfs, conv_layer, 0.9, cbs=callbacks)
with Hooks(learn.model, append_stats) as hooks:
run.fit(1, learn)
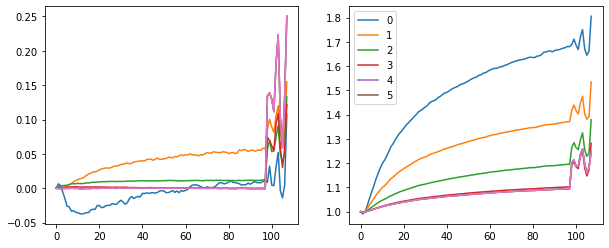
fig, (ax0, ax1) = plt.subplots(1,2, figsize=(10,4))
for h in hooks[:-1]:
ms, ss = h.stats[0], h.stats[1]
ax0.plot(ms[:10])
ax1.plot(ss[:10])
plt.legend(range(6))
fig, (ax0, ax1) = plt.subplots(1,2, figsize=(10,4))
for h in hooks[:-1]:
ms, ss = h.stats[0], h.stats[1]
ax0.plot(ms)
ax1.plot(ss)
plt.legend(range(6))
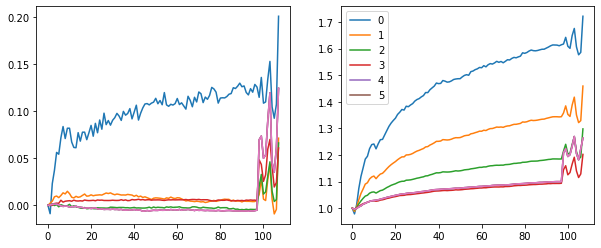
Accuracy improved.
But what is happening in the last iterations? The means and stds start jumping around. Those are the validations batches...
learn, run = get_learn_run(data, nfs, conv_layer, 1.0, cbs=callbacks)
run.fit(4, learn)
Pytorch BatchNorm Module¶
And now for the Pytorch nn.BatchNorm2d module:
#export
def conv_layer(ni, nf, ks=3, stride=2, bn=True, **kwargs):
# no bias if using bn
layers = [nn.Conv2d(ni, nf, kernel_size=ks, padding=ks//2, stride=stride, bias=not bn), GeneralRelu(**kwargs)]
if bn: layers.append(nn.BatchNorm2d(nf, eps=1e-05, momentum=0.1))
return nn.Sequential(*layers)
learn, run = get_learn_run(data, nfs, conv_layer, 0.7, cbs=callbacks)
%time run.fit(4, learn)
To improve this even more let's add our param scheduler callback:
sched = combine_scheds([0.3, 0.7], [sched_lin(0.6, 2.), sched_lin(2., 0.1)])
learn, run = get_learn_run(data, nfs, conv_layer, 0.7, cbs=callbacks+[partial(ParamScheduler, 'lr', sched)])
run.fit(8, learn)
We're at 98.7% accuracy for our validation set - that means we're wrong on about 650 out of the 50,000 digits we see.
49350 / len(data.valid_ds)
Layer Norm¶
From the paper: "batch normalization cannot be applied to online learning tasks or to extremely large distributed models where the minibatches have to be small".
class LayerNorm(nn.Module):
__constants__ = ['eps']
def __init__(self, eps=1e-5):
super().__init__()
self.eps = eps
self.mult= nn.Parameter(tensor(1.)) # learnable gamma and beta
self.add = nn.Parameter(tensor(0.))
def forward(self,x):
m = x.mean((1,2,3), keepdim=True) # mean of each image
v = x.var((1,2,3), keepdim=True)
x = (x-m) / ((v - self.eps).sqrt())
return x*self.mult + self.add
def conv_ln(ni, nf, ks=3, stride=2, bn=True, **kwargs):
layers = [nn.Conv2d(ni, nf, ks, padding=ks//2, stride=stride, bias=True),
GeneralRelu(**kwargs)]
if bn: layers.append(LayerNorm())
return nn.Sequential(*layers)
learn,run = get_learn_run(data, nfs, conv_ln, 0.8, cbs=callbacks)
run.fit(1, learn)
Not working...
Instance Norm¶
From the paper:
The key difference between contrast and batch normalization is that the latter applies the normalization to a whole batch of images instead for single ones:
\begin{equation}\label{eq:bnorm} y_{tijk} = \frac{x_{tijk} - \mu_{i}}{\sqrt{\sigma_i^2 + \epsilon}}, \quad \mu_i = \frac{1}{HWT}\sum_{t=1}^T\sum_{l=1}^W \sum_{m=1}^H x_{tilm}, \quad \sigma_i^2 = \frac{1}{HWT}\sum_{t=1}^T\sum_{l=1}^W \sum_{m=1}^H (x_{tilm} - mu_i)^2. \end{equation}In order to combine the effects of instance-specific normalization and batch normalization, we propose to replace the latter by the instance normalization (also known as contrast normalization) layer:
\begin{equation}\label{eq:inorm} y_{tijk} = \frac{x_{tijk} - \mu_{ti}}{\sqrt{\sigma_{ti}^2 + \epsilon}}, \quad \mu_{ti} = \frac{1}{HW}\sum_{l=1}^W \sum_{m=1}^H x_{tilm}, \quad \sigma_{ti}^2 = \frac{1}{HW}\sum_{l=1}^W \sum_{m=1}^H (x_{tilm} - mu_{ti})^2. \end{equation}class InstanceNorm(nn.Module):
__constants__ = ['eps']
def __init__(self, nf, eps=1e-0):
super().__init__()
self.eps = eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
def forward(self, x):
m = x.mean((2,3), keepdim=True)
v = x.var ((2,3), keepdim=True)
res = (x-m) / ((v+self.eps).sqrt())
return res*self.mults + self.adds
def conv_in(ni, nf, ks=3, stride=2, bn=True, **kwargs):
layers = [nn.Conv2d(ni, nf, ks, padding=ks//2, stride=stride, bias=True),
GeneralRelu(**kwargs)]
if bn: layers.append(InstanceNorm(nf))
return nn.Sequential(*layers)
learn,run = get_learn_run(data, nfs, conv_in, 0.8, cbs=callbacks)
run.fit(1, learn)
Group Norm¶
Fix Small Batch Sizes¶
The problem with small Batches and BatchNorm¶
Let's reload our DataBunch is a batch size of 2 and attempt to train.
data = DataBunch(*get_dls(train_ds, valid_ds, 2), c)
def conv_layer(ni, nf, ks=3, stride=2, bn=True, **kwargs):
# no bias if using bn
layers = [nn.Conv2d(ni, nf, kernel_size=ks, padding=ks//2, stride=stride, bias=not bn), GeneralRelu(**kwargs)]
if bn: layers.append(nn.BatchNorm2d(nf, eps=1e-05, momentum=0.1))
return nn.Sequential(*layers)
learn, run = get_learn_run(data, nfs, conv_layer, 0.3, cbs=callbacks)
%time run.fit(2, learn)
First thing to note is how long it takes, more than for 4 minutes for 2 epochs.
Secondly, the loss gets blown out.
"When we compute the statistics (mean and std) for a BatchNorm Layer on a small batch, it is possible that we get a standard deviation very close to 0. because there aren't many samples (the variance of one thing is 0. since it's equal to its mean)."Let's try to understand this in more detail by running a mini-batch through our first layer of our trained model to see what the output looks like after a manual BatchNorm:
xb, yb = next(iter(data.train_dl));
xb = xb.view(2, 1, 28, 28).cuda(); xb.shape
out = F.relu(learn.model[0][0](xb)); out.shape
out_mean = out.mean((0,2,3), keepdim=True)
out_var = out.var((0,2,3), keepdim=True)
Without adding the epsilon sqrt, the denominator, is zero in a few places. This means we're dividing by zero.
out_var.sqrt()
The result, even with adding a small epsilon, is not good.
Portions of the activations have gone to zero.
(out - out_mean).div(out_var.add_(1e-5).sqrt())
Running BatchNorm¶
Fastai proposed this solution to smooth the mean and variance to fix the small batch problem with BatchNorm.
class RunningBatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom,self.eps = mom,eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('sums', torch.zeros(1,nf,1,1))
self.register_buffer('sqrs', torch.zeros(1,nf,1,1))
self.register_buffer('batch', tensor(0.))
self.register_buffer('count', tensor(0.))
self.register_buffer('step', tensor(0.))
self.register_buffer('dbias', tensor(0.))
def update_stats(self, x):
bs,nc,*_ = x.shape
self.sums.detach_()
self.sqrs.detach_()
dims = (0,2,3)
s = x.sum(dims, keepdim=True)
ss = (x*x).sum(dims, keepdim=True)
c = self.count.new_tensor(x.numel()/nc)
mom1 = 1 - (1-self.mom)/math.sqrt(bs-1)
self.mom1 = self.dbias.new_tensor(mom1)
self.sums.lerp_(s, self.mom1)
self.sqrs.lerp_(ss, self.mom1)
self.count.lerp_(c, self.mom1)
self.dbias = self.dbias*(1-self.mom1) + self.mom1
self.batch += bs
self.step += 1
def forward(self, x):
if self.training: self.update_stats(x)
sums = self.sums
sqrs = self.sqrs
c = self.count
if self.step<100:
sums = sums / self.dbias
sqrs = sqrs / self.dbias
c = c / self.dbias
means = sums/c
vars = (sqrs/c).sub_(means*means)
if bool(self.batch < 20): vars.clamp_min_(0.01)
x = (x-means).div_((vars.add_(self.eps)).sqrt())
return x.mul_(self.mults).add_(self.adds)
def conv_rbn(ni, nf, ks=3, stride=2, bn=True, **kwargs):
layers = [nn.Conv2d(ni, nf, ks, padding=ks//2, stride=stride, bias=not bn),
GeneralRelu(**kwargs)]
if bn: layers.append(RunningBatchNorm(nf))
return nn.Sequential(*layers)
learn,run = get_learn_run(data, nfs, conv_rbn, 0.4, cbs=callbacks)
%time run.fit(1, learn)
Running BatchNorm appears to fix the problem of small batches.
Best Single Epoch¶
Now we'll use a somewhat larger batch size of 32 and see the best accuracy we can attain.
data = DataBunch(*get_dls(train_ds, valid_ds, 32), c)
learn,run = get_learn_run(data,nfs, conv_rbn, 0.9, cbs=callbacks
+[partial(ParamScheduler,'lr', sched_lin(1., 0.2))])
%time run.fit(1, learn)
Time to play around with our param scheduler and see if we can find a sweet spot...
sched = combine_scheds([.2, .8], [sched_cos(.1, 0.9), sched_cos(.9, .7)])
learn,run = get_learn_run(data,nfs, conv_rbn, 0.9, cbs=callbacks
+[partial(ParamScheduler,'lr', sched)])
%time run.fit(1, learn)
sched = combine_scheds([.5, .5], [sched_cos(.5, 1.), sched_cos(1., .09)])
learn,run = get_learn_run(data,nfs, conv_rbn, 0.9, cbs=callbacks
+[partial(ParamScheduler,'lr', sched)])
%time run.fit(1, learn)
sched = combine_scheds([.7, .3], [sched_cos(.6, 1.1), sched_cos(1.1, .2)])
learn,run = get_learn_run(data,nfs, conv_rbn, 0.9, cbs=callbacks
+[partial(ParamScheduler,'lr', sched)])
%time run.fit(1, learn)
sched = combine_scheds([.4, .6], [sched_cos(.2, 1.1), sched_cos(1.1, .2)])
learn,run = get_learn_run(data,nfs, conv_rbn, 0.9, cbs=callbacks
+[partial(ParamScheduler,'lr', sched)])
%time run.fit(1, learn)
sched = combine_scheds([.5, .5], [sched_cos(.4, 1.2), sched_cos(1.2, .2)])
learn,run = get_learn_run(data,nfs, conv_rbn, 0.9, cbs=callbacks
+[partial(ParamScheduler,'lr', sched)])
%time run.fit(1, learn)
sched = combine_scheds([.5, .5], [sched_cos(.4, 1.3), sched_cos(.8, .5)])
learn,run = get_learn_run(data,nfs, conv_rbn, 0.9, cbs=callbacks
+[partial(ParamScheduler,'lr', sched)])
%time run.fit(1, learn)
sched = combine_scheds([.5, .5], [sched_cos(.4, 1.3), sched_cos(.8, .5)])
learn,run = get_learn_run(data,nfs, conv_rbn, 0.9, cbs=callbacks
+[partial(ParamScheduler,'lr', sched)])
%time run.fit(1, learn)
nb_auto_export()