%reload_ext autoreload
%autoreload 2
%matplotlib inline
Recorder and Annealing¶
Parameter Scheduling
#export
from exp.nb_04 import *
import torch.nn.functional as F
import torch.nn as nn
from functools import partial
Get Data¶
x_train, y_train, x_valid, y_valid = get_data()
train_ds, valid_ds = Dataset(x_train, y_train), Dataset(x_valid, y_valid)
nh = 50
bs = 512
c = y_train.max().item()+1
loss_func = F.cross_entropy
data = DataBunch(*get_dls(train_ds, valid_ds, bs), c=c)
Create Learner and Test¶
#export
def create_learner(model_func, loss_func, data):
return Learner(*model_func(data),loss_func, data)
learn = create_learner(get_model, loss_func, data)
run = Runner(cbs=[AvgStatsCallback(accuracy)])
run.fit(3, learn)
To change the learning rate we need to change the get_model default arg and pass it along to create_learner we do this with a partial:
learn = create_learner(partial(get_model, lr=0.3), loss_func, data)
run = Runner(cbs=[AvgStatsCallback(accuracy)])
run.fit(3, learn)
So we can wrap that partial in a function:
#export
def get_model_func(lr=0.5): return partial(get_model, lr=lr)
Recorder & Parameter Scheduling¶
Recent research has demonstrated the importance of varying certain parameters over the course of a training epoch.
Hyper-parameters like learning rate, momentum, and weight decay should be tuned and change according to the position in the training.
To do this we'll make two callbacks:
Recorderwhich will track (or record) the loss and any other parameter we wantParamSchedulerwhich will change any parameter that is registered in our optimizer param dict.
Let's start with the Recorder
#export
class Callback():
_order = 0
def set_runner(self, run):
self.run = run
def __getattr__(self, k):
return getattr(self.run, k)
@property
def name(self):
name = re.sub(r'Callback$', '', self.__class__.__name__) # removes Callback from custom callback class name
return camel2snake(name or "callback")
#export
class Recorder(Callback):
def begin_fit(self):
self.losses = []
self.lrs = []
def after_step(self):
if not self.in_train: return # don't
self.losses.append(self.loss.detach().cpu())
self.lrs.append(self.opt.param_groups[-1]['lr'])
def plot_losses(self):
plt.plot(self.losses)
def plot_lr(self):
plt.plot(self.lrs)
learn = create_learner(get_model_func(), loss_func, data)
run = Runner(cb_funcs=[AvgStatsCallback(accuracy), Recorder()])
run.fit(3, learn)
Alright our recorder is working. We can plot the losses:
run.recorder.plot_losses()
We can also plot the learning rate:
run.recorder.plot_lr()

The learning rate here is constant for the entire duration of the epoch.
Let's fix that with a ParamScheduler callback:
#export
class ParamScheduler(Callback):
_order = 1
def __init__(self, pname, sched_func):
self.pname = pname
self.sched_func = sched_func
def set_param(self):
for pg in self.opt.param_groups:
pg[self.pname] = self.sched_func(self.n_epochs/self.epochs)
def begin_batch(self):
if self.in_train: self.set_param()
Schedulers¶
Let's start easy with a linear scheduler.
We want a function that takes a place to start, an end, and the number of steps to take.
The start and end should be established before training starts and the function should then take in the current position and return the value.
We'll have to use partial for this.
def linsched(start, stop):
def _inner(start, stop, pos): return start + (stop - start) * pos
return partial(_inner, start, stop)
start = 0.1
end = 0.5
ls = linsched(start, end)
ls(.75)
A more pythonic and cleaner way of doing this would be to use a decorator:
#export
def annealer(f):
def _inner(start, end): return partial(f, start, end)
return _inner
@annealer
def sched_lin(start, end, pos): return start + (end -start) * pos
start = 0.1
end = 0.5
ls = sched_lin(start, end)
ls(.75)
Now we can use this decorator and define simple sched functions.
They take start and end args to initialize and then are called with a percentage of the epoch (between 0 - 1) and return a parameter value at that position.
The first and most obvious is sched_no which does nothing.
#export
import math
@annealer
def sched_no(start, end, pos): return start
@annealer
def sched_cos(start, end, pos): return start + (1 + math.cos(math.pi*(1-pos))) * (end-start) / 2
@annealer
def sched_exp(start, end, pos): return start * (end/start) ** pos
#export
def cos_1cycle_anneal(start, high, end):
return [sched_cos(start, high), sched_cos(high, end)]
Plotting the different schedulers gives a clear picture of what they are doing over the course of an epoch.
annealings = "NO LINEAR COS EXP".split()
iterations = torch.arange(0,100)
pos = torch.linspace(0.01, 1, 100)
funcs = [sched_no, sched_lin, sched_cos, sched_exp]
for fn, title in zip(funcs, annealings):
f = fn(1e-04, 3e-2)
plt.plot(iterations, [f(o) for o in pos], label=title)
plt.xlabel("Iterations")
plt.ylabel("Param Value")
plt.legend()
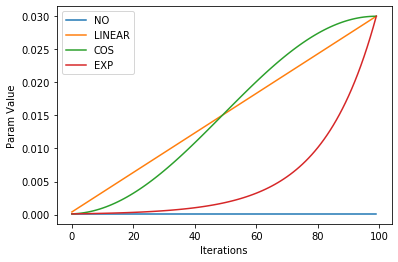
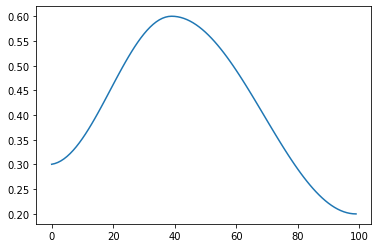
The tricker part of scheduling is combining these functions together to design how our parameters are scheduled. We don't necessary want them to increase linearly, exponentially, or like a cosine.
#export
def combine_scheds(pcts, scheds):
assert sum(pcts) == 1.
pcts = tensor([0] + listify(pcts))
assert torch.all(pcts>=0)
pcts = torch.cumsum(pcts, 0)
def _inner(pos):
idx = (pos >= pcts).nonzero().max()
actual_pos = (pos-pcts[idx]) / (pcts[idx+1]-pcts[idx])
return scheds[idx](actual_pos)
return _inner
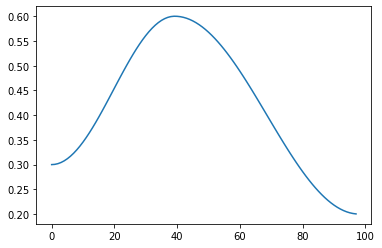
sched = combine_scheds([0.4, 0.6], [sched_cos(0.3, 0.6), sched_cos(0.6, 0.2)])
pos = torch.linspace(0.01, 1, 100)
plt.plot(iterations, [sched(o) for o in pos])
Testing¶
scheduler = partial(ParamScheduler, 'lr', sched)
learn = create_learner(get_model_func(0.3), loss_func, data)
run = Runner(cbs=[AvgStatsCallback(accuracy), scheduler()], cb_funcs=Recorder())
run.fit(1, learn)
run.recorder.plot_losses()
run.recorder.plot_lr()
!python notebook2script.py 05_recorder_annealing.ipynb